Thursday, November 08, 2018
Kubernetes Docs Updates, International Edition
Author: Zach Corleissen (Linux Foundation)
As a co-chair of SIG Docs, I’m excited to share that Kubernetes docs have a fully mature workflow for localization (l10n).
Abbreviations galore
L10n is an abbreviation for localization.
I18n is an abbreviation for internationalization.
I18n is what you do to make l10n easier. L10n is a fuller, more comprehensive process than translation (t9n).
Why localization matters
The goal of SIG Docs is to make Kubernetes easier to use for as many people as possible.
One year ago, we looked at whether it was possible to host the output of a Chinese team working independently to translate the Kubernetes docs. After many conversations (including experts on OpenStack l10n), much transformation, and renewed commitment to easier localization, we realized that open source documentation is, like open source software, an ongoing exercise at the edges of what’s possible.
Consolidating workflows, language labels, and team-level ownership may seem like simple improvements, but these features make l10n scalable for increasing numbers of l10n teams. While SIG Docs continues to iterate improvements, we’ve paid off a significant amount of technical debt and streamlined l10n in a single workflow. That’s great for the future as well as the present.
Consolidated workflow
Localization is now consolidated in the kubernetes/website repository. We’ve configured the Kubernetes CI/CD system, Prow, to handle automatic language label assignment as well as team-level PR review and approval.
Language labels
Prow automatically applies language labels based on file path. Thanks to SIG Docs contributor June Yi, folks can also manually assign language labels in pull request (PR) comments. For example, when left as a comment on an issue or PR, this command assigns the label language/ko (Korean).
/language ko
These repo labels let reviewers filter for PRs and issues by language. For example, you can now filter the k/website dashboard for PRs with Chinese content.
Team review
L10n teams can now review and approve their own PRs. For example, review and approval permissions for English are assigned in an OWNERS file in the top subfolder for English content.
Adding OWNERS files to subdirectories lets localization teams review and approve changes without requiring a rubber stamp approval from reviewers who may lack fluency.
What’s next
We’re looking forward to the doc sprint in Shanghai to serve as a resource for the Chinese l10n team.
We’re excited to continue supporting the Japanese and Korean l10n teams, who are making excellent progress.
If you’re interested in localizing Kubernetes for your own language or region, check out our guide to localizing Kubernetes docs and reach out to a SIG Docs chair for support.
Get involved with SIG Docs
If you’re interested in Kubernetes documentation, come to a SIG Docs weekly meeting, or join #sig-docs in Kubernetes Slack.
2018.10.03
KubeDirector:在 Kubernetes 上运行复杂状态应用程序的简单方法
作者:Thomas Phelan(BlueData)
KubeDirector 是一个开源项目,旨在简化在 Kubernetes 上运行复杂的有状态扩展应用程序集群。KubeDirector 使用自定义资源定义(CRD) 框架构建,并利用了本地 Kubernetes API 扩展和设计哲学。这支持与 Kubernetes 用户/资源 管理以及现有客户端和工具的透明集成。
我们最近介绍了 KubeDirector 项目,作为我们称为 BlueK8s 的更广泛的 Kubernetes 开源项目的一部分。我很高兴地宣布 KubeDirector 的 pre-alpha 代码现在已经可用。在这篇博客文章中,我将展示它是如何工作的。
KubeDirector 提供以下功能:
- 无需修改代码即可在 Kubernetes 上运行非云原生有状态应用程序。换句话说,不需要分解这些现有的应用程序来适应微服务设计模式。
- 本机支持保存特定于应用程序的配置和状态。
- 与应用程序无关的部署模式,最大限度地减少将新的有状态应用程序装载到 Kubernetes 的时间。
KubeDirector 使熟悉数据密集型分布式应用程序(如 Hadoop、Spark、Cassandra、TensorFlow、Caffe2 等)的数据科学家能够在 Kubernetes 上运行这些应用程序 – 只需极少的学习曲线,无需编写 GO 代码。由 KubeDirector 控制的应用程序由一些基本元数据和相关的配置工件包定义。应用程序元数据称为 KubeDirectorApp 资源。
要了解 KubeDirector 的组件,请使用类似于以下的命令在 GitHub 上克隆存储库:
git clone http://<userid>@github.com/bluek8s/kubedirector.
Spark 2.2.1 应用程序的 KubeDirectorApp 定义位于文件 kubedirector/deploy/example_catalog/cr-app-spark221e2.json 中。
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{
"apiVersion": "kubedirector.bluedata.io/v1alpha1",
"kind": "KubeDirectorApp",
"metadata": {
"name" : "spark221e2"
},
"spec" : {
"systemctlMounts": true,
"config": {
"node_services": [
{
"service_ids": [
"ssh",
"spark",
"spark_master",
"spark_worker"
],
…
应用程序集群的配置称为 KubeDirectorCluster 资源。示例 Spark 2.2.1 集群的 KubeDirectorCluster 定义位于文件
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml 中。
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1"
kind: "KubeDirectorCluster"
metadata:
name: "spark221e2"
spec:
app: spark221e2
roles:
- name: controller
replicas: 1
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: worker
replicas: 2
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: jupyter
…
使用 KubeDirector 在 Kubernetes 上运行 Spark
使用 KubeDirector,可以轻松在 Kubernetes 上运行 Spark 集群。
首先,使用命令 kubectl version 验证 Kubernetes(版本 1.9 或更高)是否正在运行
~> kubectl version
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
使用以下命令部署 KubeDirector 服务和示例 KubeDirectorApp 资源定义:
cd kubedirector
make deploy
这些将启动 KubeDirector pod:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
kubectl get KubeDirectorApp 列出中已安装的 KubeDirector 应用程序
~> kubectl get KubeDirectorApp
NAME AGE
cassandra311 30m
spark211up 30m
spark221e2 30m
现在,您可以使用示例 KubeDirectorCluster 文件和 kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml 命令
启动 Spark 2.2.1 集群。验证 Spark 集群已经启动:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-djdwl 1/1 Running 0 19m
spark221e2-controller-zbg4d-0 1/1 Running 0 23m
spark221e2-jupyter-2km7q-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-1 1/1 Running 0 23m
现在运行的服务包括 Spark 服务:
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
将浏览器指向端口 31533 连接到 Spark 主节点 UI:
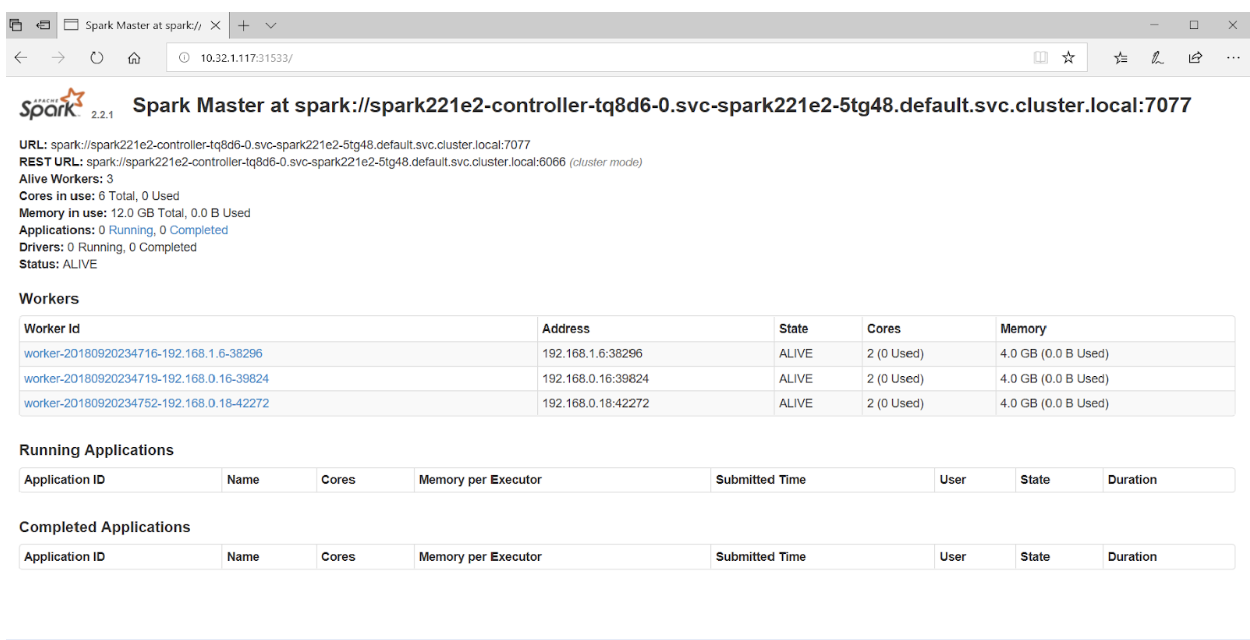
就是这样! 事实上,在上面的例子中,我们还部署了一个 Jupyter notebook 和 Spark 集群。
要启动另一个应用程序(例如 Cassandra),只需指定另一个 KubeDirectorApp 文件:
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
查看正在运行的 Cassandra 集群:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
cassandra311-seed-v24r6-0 1/1 Running 0 1m
cassandra311-seed-v24r6-1 1/1 Running 0 1m
cassandra311-worker-rqrhl-0 1/1 Running 0 1m
cassandra311-worker-rqrhl-1 1/1 Running 0 1m
kubedirector-58cf59869-djdwl 1/1 Running 0 1d
spark221e2-controller-tq8d6-0 1/1 Running 0 22m
spark221e2-jupyter-6989v-0 1/1 Running 0 22m
spark221e2-worker-d9892-0 1/1 Running 0 22m
spark221e2-worker-d9892-1 1/1 Running 0 22m
现在,您有一个 Spark 集群(带有 Jupyter notebook )和一个运行在 Kubernetes 上的 Cassandra 集群。
使用 kubectl get service 查看服务集。
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m
svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m
svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m
svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m
svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
参与其中
KubeDirector 是一个完全开放源码的 Apache v2 授权项目 – 在我们称为 BlueK8s 的更广泛的计划中,它是多个开放源码项目中的第一个。 KubeDirector 的 pre-alpha 代码刚刚发布,我们希望您加入到不断增长的开发人员、贡献者和使用者社区。 在 Twitter 上关注 @BlueK8s,并通过以下渠道参与: